大數(shù)據(jù)分析工具全解析 免費(fèi)與付費(fèi)選擇指南
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的時(shí)代,大數(shù)據(jù)分析已成為企業(yè)決策與業(yè)務(wù)優(yōu)化的核心。無(wú)論是初創(chuàng)公司還是大型企業(yè),選擇合適的數(shù)據(jù)分析工具都至關(guān)重要。本文將系統(tǒng)性地介紹當(dāng)前市場(chǎng)上主流的大數(shù)據(jù)分析工具,涵蓋免費(fèi)開(kāi)源選項(xiàng)與優(yōu)秀付費(fèi)解決方案,并探討數(shù)據(jù)處理的關(guān)鍵環(huán)節(jié)。
一、 免費(fèi)開(kāi)源大數(shù)據(jù)分析工具
免費(fèi)開(kāi)源工具以其靈活性、社區(qū)支持和低成本優(yōu)勢(shì),成為許多團(tuán)隊(duì)入門和構(gòu)建分析體系的首選。
1. Apache Hadoop:
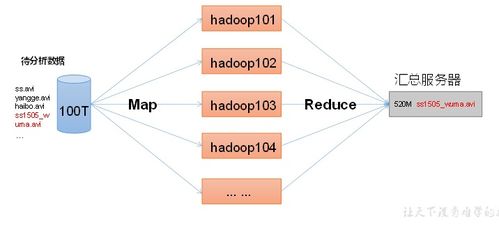
作為分布式處理框架的基石,Hadoop生態(tài)系統(tǒng)(包括HDFS, MapReduce, YARN)為海量數(shù)據(jù)存儲(chǔ)與批處理提供了強(qiáng)大支持。它是構(gòu)建大規(guī)模數(shù)據(jù)處理平臺(tái)的基礎(chǔ)。
2. Apache Spark:
憑借其內(nèi)存計(jì)算引擎,Spark在速度上遠(yuǎn)超傳統(tǒng)的MapReduce。它支持批處理、實(shí)時(shí)流處理、機(jī)器學(xué)習(xí)和圖計(jì)算,是當(dāng)前最活躍的大數(shù)據(jù)開(kāi)源項(xiàng)目之一。
3. Apache Flink:
專注于流處理,提供真正的流式處理能力和精確一致的容錯(cuò)機(jī)制,在實(shí)時(shí)分析場(chǎng)景中表現(xiàn)出色。
4. Elasticsearch + Kibana (ELK Stack):
強(qiáng)大的搜索與分析引擎Elasticsearch,配合數(shù)據(jù)可視化工具Kibana,構(gòu)成了日志和指標(biāo)數(shù)據(jù)實(shí)時(shí)搜索、分析與可視化的黃金組合。
5. Apache Kafka:
高吞吐量的分布式消息系統(tǒng),是構(gòu)建實(shí)時(shí)數(shù)據(jù)管道和流應(yīng)用的核心,負(fù)責(zé)數(shù)據(jù)的可靠采集與傳輸。
6. R 與 Python (Pandas, NumPy, Scikit-learn):
雖然不是端到端的平臺(tái),但R語(yǔ)言和Python及其豐富的數(shù)據(jù)科學(xué)庫(kù)(如Pandas, Scikit-learn)是進(jìn)行數(shù)據(jù)清洗、探索性分析和建模的利器。
這些工具通常需要較強(qiáng)的技術(shù)團(tuán)隊(duì)進(jìn)行集成、部署和維護(hù)。
二、 優(yōu)秀付費(fèi)(商業(yè))大數(shù)據(jù)分析平臺(tái)
付費(fèi)平臺(tái)通常提供一體化的解決方案、企業(yè)級(jí)支持、安全合規(guī)保障和更友好的用戶界面,能顯著降低使用門檻并提升效率。
- AWS, Azure, GCP 云數(shù)據(jù)平臺(tái):
- 亞馬遜AWS (Amazon EMR, Redshift, Athena):提供全面的托管Hadoop/Spark服務(wù)、數(shù)據(jù)倉(cāng)庫(kù)和交互式查詢服務(wù),生態(tài)成熟。
- 微軟Azure (Azure Synapse Analytics, HDInsight):深度集成微軟生態(tài),Synapse Analytics將數(shù)據(jù)集成、數(shù)據(jù)倉(cāng)庫(kù)和大數(shù)據(jù)分析統(tǒng)一起來(lái)。
- 谷歌云GCP (BigQuery, Dataproc):BigQuery是完全托管、無(wú)服務(wù)器的企業(yè)級(jí)數(shù)據(jù)倉(cāng)庫(kù),以極快的SQL查詢速度和易用性著稱。
2. Snowflake:
專為云構(gòu)建的數(shù)據(jù)平臺(tái),將存儲(chǔ)、計(jì)算和服務(wù)分離,提供了極高的彈性、并發(fā)性能和易用性,支持跨云部署,是數(shù)據(jù)倉(cāng)庫(kù)領(lǐng)域的明星產(chǎn)品。
3. Databricks:
由Apache Spark的創(chuàng)始人創(chuàng)建,提供統(tǒng)一的“數(shù)據(jù)+AI”平臺(tái)(Lakehouse架構(gòu)),優(yōu)化了Spark的性能和管理,集成了數(shù)據(jù)工程、數(shù)據(jù)科學(xué)和商業(yè)分析工作流。
- Tableau / Power BI (側(cè)重分析與可視化):
- Tableau:在數(shù)據(jù)可視化方面領(lǐng)先,能夠連接多種數(shù)據(jù)源,通過(guò)拖拽式界面快速生成交互式、高質(zhì)量的儀表板。
- Microsoft Power BI:與Office 365深度集成,提供從數(shù)據(jù)準(zhǔn)備、建模到可視化分享的完整流程,性價(jià)比高,企業(yè)普及率廣。
5. SAS Viya / IBM SPSS Modeler:
老牌的高級(jí)分析與預(yù)測(cè)建模平臺(tái),提供豐富的統(tǒng)計(jì)分析和機(jī)器學(xué)習(xí)算法,在金融、醫(yī)療等對(duì)模型可解釋性和穩(wěn)定性要求高的行業(yè)廣泛應(yīng)用。
三、 數(shù)據(jù)處理:分析流程的核心
無(wú)論選擇何種工具,有效的數(shù)據(jù)處理流程都是成功分析的前提。它通常包含以下關(guān)鍵階段:
- 數(shù)據(jù)采集與集成:從數(shù)據(jù)庫(kù)、API、日志文件、物聯(lián)網(wǎng)設(shè)備等多源異構(gòu)系統(tǒng)中收集數(shù)據(jù)。工具如Kafka, Flume, Sqoop, 以及云服務(wù)的Data Pipeline/Azure Data Factory等在此階段發(fā)揮作用。
- 數(shù)據(jù)存儲(chǔ)與管理:將數(shù)據(jù)存儲(chǔ)在合適的系統(tǒng)中,如分布式文件系統(tǒng)(HDFS)、數(shù)據(jù)湖(AWS S3, Azure Data Lake)、數(shù)據(jù)倉(cāng)庫(kù)(Redshift, Snowflake, BigQuery)或NoSQL數(shù)據(jù)庫(kù)(HBase, Cassandra)。
- 數(shù)據(jù)清洗與轉(zhuǎn)換:處理缺失值、異常值、格式不一致等問(wèn)題,并進(jìn)行聚合、關(guān)聯(lián)等轉(zhuǎn)換,為分析做準(zhǔn)備。Spark, Pandas, Talend, 以及SQL是常用工具。
- 數(shù)據(jù)分析與建模:應(yīng)用統(tǒng)計(jì)分析、機(jī)器學(xué)習(xí)算法來(lái)發(fā)現(xiàn)模式、預(yù)測(cè)趨勢(shì)。Spark MLlib, Python/R庫(kù),以及Databricks、SAS等平臺(tái)提供強(qiáng)大支持。
- 數(shù)據(jù)可視化與洞察呈現(xiàn):將分析結(jié)果通過(guò)圖表、儀表板等形式直觀呈現(xiàn),輔助決策。Kibana, Tableau, Power BI, Superset是典型代表。
四、 如何選擇?
- 評(píng)估需求:明確分析的數(shù)據(jù)規(guī)模(GB/TB/PB?)、實(shí)時(shí)性要求(批量/實(shí)時(shí)?)、團(tuán)隊(duì)技能(編程能力/業(yè)務(wù)分析?)和預(yù)算。
- 免費(fèi)工具:適合技術(shù)實(shí)力強(qiáng)、需要高度定制化、預(yù)算有限的團(tuán)隊(duì)或?qū)W習(xí)研究用途。
- 付費(fèi)平臺(tái):適合追求開(kāi)發(fā)效率、需要快速上線、缺乏專門運(yùn)維團(tuán)隊(duì)或?qū)Π踩⒅С钟懈邩?biāo)準(zhǔn)要求的企業(yè)。
- 混合策略:常見(jiàn)做法是使用開(kāi)源工具(如Spark, Kafka)處理核心數(shù)據(jù)管道,同時(shí)采用商業(yè)產(chǎn)品(如Snowflake, Tableau)進(jìn)行數(shù)據(jù)存儲(chǔ)和前端分析,實(shí)現(xiàn)成本與效益的平衡。
總而言之,大數(shù)據(jù)分析工具的選擇沒(méi)有“唯一最優(yōu)解”。理解免費(fèi)工具的潛力與局限,認(rèn)識(shí)付費(fèi)平臺(tái)帶來(lái)的價(jià)值,并結(jié)合自身的數(shù)據(jù)處理需求與技術(shù)路線進(jìn)行綜合考量,才能構(gòu)建出高效、可持續(xù)的數(shù)據(jù)分析體系。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.7bq85.cn/product/1.html
更新時(shí)間:2026-06-18 22:35:02